Artefakty muzyka AI i jakość brzmienia - obecne ograniczenia
Dlaczego utwory AI brzmią metalicznie? Poznaj techniczne ograniczenia i artefakty muzyki AI oraz proste metody ich unikania w codziennej pracy z generatorami.

📑 W tym artykule
- Jakie są główne ograniczenia generatorów muzyki i skąd biorą się artefakty?
- Jakie problemy z jakością dźwięku piosenek AI słychać najczęściej?
- Szumy, brzęki i metaliczny pogłos
- Dystorsje przejściowe i problemy z wymową (lipsync)
- Czy AI tworzy realistyczną muzykę i potrafi oszukać ludzkie ucho?
- Jak zminimalizować defekty techniczne piosenek sztucznej inteligencji?
- Inżynieria promptu (Tagi i Sterowanie)
- Postprodukcja i oczyszczanie spektralne (Spectral Cleaning)
- Często zadawane pytania o błędy i jakość muzyki AI
- Dlaczego piosenki AI często psują się na końcu utworu?
- Czy kolejne wersje AI naprawią metaliczny pogłos?
- Czy generowanie tego samego promptu da lepszą jakość?
- Podsumowanie: Perspektywy rozwoju i realne granice technologii
- Technologia generowania muzyki zachwyca, ale wciąż potyka się o stratną kompresję przestrzeni ukrytej (latent space).
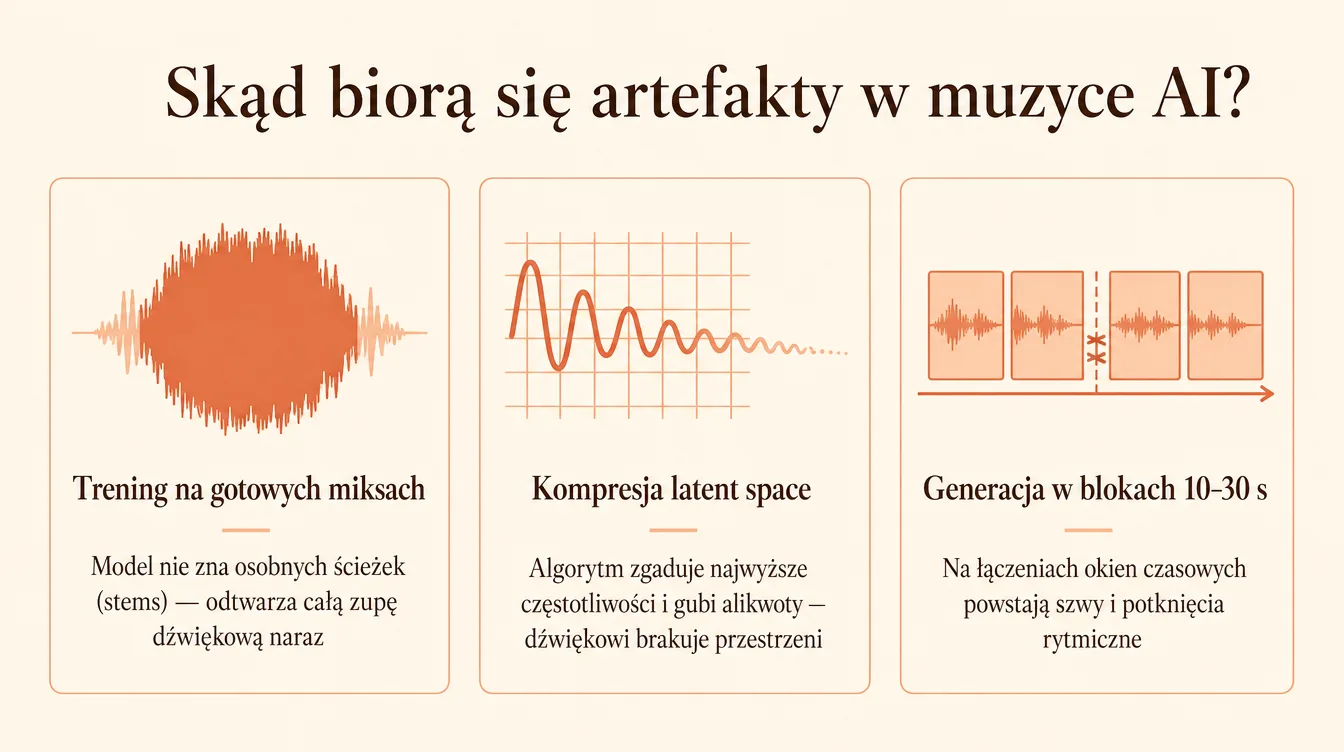
- Modele uczą się na zgranych, gotowych utworach, a nie na wyodrębnionych ścieżkach instrumentów (stems).
- Większość problemów z jakością da się skutecznie ratować precyzyjnym promptowaniem i darmowymi poprawkami (re-render).
Odpalasz generator. Słuchasz pierwszych sekund. Uśmiechasz się. Gitara brzmi w punkt, wokalista ma świetną barwę. A potem, gdzieś w połowie zwrotki, słyszysz to. Dziwny, metaliczny pogłos. Słowa zlewają się w jedną masę. Dźwięk przypomina starą empetrójkę pobraną z kiepskiego serwera w 2005 roku. Magia pryska. Ograniczenia generatorów muzyki to brutalna rzeczywistość, a specyficzne artefakty muzyki AI słychać niemal w każdym amatorskim nagraniu.
Sztuczna inteligencja tworzy dziś niesamowite rzeczy, ale wciąż walczy z syntetycznym nalotem i wokalnymi halucynacjami. Dlaczego tak się dzieje? Rozkładamy problemy z jakością dźwięku piosenek AI na czynniki pierwsze. Bez technicznego bełkotu. Tłumaczymy, co dokładnie słyszysz, skąd to się bierze i jak to obejść. Wszystko po to, abyś miał realistyczne oczekiwania i wiedział, jak wycisnąć z tej technologii maksimum.
Jakie są główne ograniczenia generatorów muzyki i skąd biorą się artefakty?
AI nie ma uszu. Nie rozumie fizyki fal dźwiękowych. Rozumie wyłącznie statystykę. Większość modeli uczy się na całkowicie zmiksowanych utworach, a nie na odseparowanych ścieżkach poszczególnych instrumentów. Wyobraź sobie, że próbujesz zrozumieć, jak działa jajko, badając wyłącznie upieczony tort. System ma dokładnie ten sam problem. Nie wie, jak osobno zachowuje się stopa perkusji, a jak uderzenie w strunę gitary basowej. Próbuje odtworzyć całość naraz.
Kolejna blokada to stratna kompresja w reprezentacji przestrzeni ukrytej (latent space). Modele muszą przetwarzać gigantyczne ilości danych. Zamiast zapamiętywać każdą częstotliwość, algorytmy „zgadują” wysokotonalne dźwięki. Gubią najwyższe alikwoty. Stąd bierze się wrażenie, że dźwiękowi brakuje oddechu i przestrzeni.
Ograniczenia czasowe to trzeci potężny problem. Silniki generują utwory w blokach. Zależnie od narzędzia są to paczki po 10–30 sekund. System tworzy pierwszy blok, a potem musi płynnie dopisać do niego drugi. Łączenie tych okien czasowych tworzy szwy. Jeśli model źle obliczy tempo na łączeniu, słyszysz potknięcie rytmiczne.
Różnice w powstawaniu dźwięku:
- Standardowe tworzenie muzyki (DAW): człowiek nagrywa czyste, odseparowane ścieżki i precyzyjnie ustala ich głośność oraz miejsce w przestrzeni stereofonicznej.
- Generowanie fal dźwiękowych (Diffusion/Transformers): model probabilistycznie tworzy gęstą zupę pełnego pasma dźwięku, opierając się na matematycznym prawdopodobieństwie wystąpienia kolejnej próbki audio po poprzedniej.
Jakie problemy z jakością dźwięku piosenek AI słychać najczęściej?
Naturalna muzyka żyje niedoskonałościami. Ludzki perkusista uderza w werbel milisekundę za wcześnie lub za późno. To buduje groove. AI dąży do matematycznej precyzji, co paradoksalnie zabija dynamikę. Brak mikrotimingu sprawia, że utwór brzmi płasko i sztywno. Ale to dopiero wierzchołek góry lodowej.
Szumy, brzęki i metaliczny pogłos
Spektralne artefakty w muzyce AI to zmora dzisiejszych generatorów. Przypomina to dźwięk mp3 o drastycznie niskim bitrate. Najbardziej cierpią na tym talerze perkusyjne (crashes). Algorytmy mają ogromny problem z ich interpretacją, ponieważ rozproszony dźwięk blachy przypomina im biały szum. Zamiast soczystego uderzenia słyszysz mechaniczne, piaszczyste syczenie, które urywa się nienaturalnie szybko.
Dystorsje przejściowe i problemy z wymową (lipsync)
Język polski to wyzwanie. Nasza mowa jest pełna szeleszczących zgłosek. Modele często doświadczają halucynacji językowych. Przekręcają skomplikowane słowa, zlewają rymy w jedną papkę. Zdarza się też efekt polifoniczny – słyszysz dwa nakładające się na siebie głosy śpiewające inne sylaby naraz. System źle zinterpretował strukturę promptu i próbuje zmieścić za dużo tekstu w zbyt krótkim fragmencie melodii.
| Typ błędu | Jak to brzmi w praktyce | Prawdopodobna przyczyna technologiczna |
|---|---|---|
| Metaliczny pogłos | Jak słaba mp3 / dzwonek na starym telefonie | Kompresja w latent space i utrata wysokich alikwotów |
| Szum talerzy perkusyjnych | Zamiast uderzenia w blachę słychać sypiący się piasek | Błędna interpretacja fal wysokich częstotliwości jako białego szumu |
| Polifonia wokalna | Dwa nakładające się na siebie, niewyraźne głosy | Niezgodność metrum z ilością sylab w prompcie |
| Zanik struktury pod koniec | Piosenka nagle zmienia gatunek lub tempo | Wyczerpanie okna kontekstowego modelu |
Czy AI tworzy realistyczną muzykę i potrafi oszukać ludzkie ucho?
Słuchając pojedynczych potknięć, łatwo uznać tę technologię za zabawkę. Prawda jest inna. Czy AI tworzy realistyczną muzykę? Badania pokazują, że zazwyczaj radzi sobie doskonale. Zestawienie przygotowane przez Deezer i Ipsos dostarcza twardych danych. Aż 97% słuchaczy nie potrafiło w pełni poprawnie wyłonić wszystkich syntetycznych utworów z przygotowanego zestawu. Trafność oceny w pojedynczych przypadkach wynosiła raptem 43%.
Nasze uszy nie są przygotowane na perfekcję. Zjawisko doliny niesamowitości (uncanny valley) w dźwięku uderza nas podświadomie. Harmonia jest wręcz zbyt poprawna, nie słychać oddechu przed trudną frazą, zwrotki brzmią identycznie pod kątem ekspresji. Suno, na którym operuje silnik Refrenik, błyskawicznie redukuje te bariery, ucząc się ludzkich zająknięć i przerw na oddech. Wciąż posiada jednak specyficzne sygnatury w obróbce wokalu. Jeśli pracujesz z dźwiękiem, usłyszysz je. Jeśli wysyłasz piosenkę mamie na 60. urodziny – nawet nie zorientuje się, że to nie jest żywy zespół w studiu.
Jak zminimalizować defekty techniczne piosenek sztucznej inteligencji?
Problemy istnieją, ale można je sprytnie ominąć. Defekty techniczne piosenek sztucznej inteligencji nie muszą niszczyć prezentu. Masz konkretne metody ratunkowe na każdym etapie tworzenia.
Jeśli pierwsza próba w Refreniku wyjdzie kiczowato, a wokalista połamie sobie język na polskim słowie, nie akceptujesz tego. Zmieniasz tag. Skracasz zdanie. Generujesz nową wersję bez dopłat. To najprostsza, najskuteczniejsza i najtańsza metoda walki z problemami modeli audio.

Inżynieria promptu (Tagi i Sterowanie)
Model gubi się, gdy każesz mu zrobić za dużo naraz. Zbyt długa linijka tekstu w zwrotce zmusza system do sprinterskiego tempa. Algorytm ściska frazy, co kończy się bełkotem. Jeśli wymuszasz wolne tempo, a tekst jest gęsty, otrzymasz nienaturalne rozciąganie sylab. Rytm tekstu musi pasować do tagów muzycznych.
Zwróć uwagę na spójność gatunkową. Nigdy nie używaj sprzecznych tagów w jednym prompcie. Wpisanie „acoustic death metal” to prośba o cyfrowy wypadek samochodowy. Model spróbuje połączyć łagodne gitary z blastami i growlem, co niemal zawsze kończy się gigantycznym chaosem aranżacyjnym i wysypem brzęczących artefaktów.
Postprodukcja i oczyszczanie spektralne (Spectral Cleaning)
Zaawansowani użytkownicy wyciągają plik z generatora i wrzucają go do swojego oprogramowania. Używają narzędzi do wyodrębniania ścieżek (stem separation), żeby oddzielić wokal od perkusji i nałożyć na niego własny korektor (EQ). To ma sens, ale szybko uderza w mur. Tradycyjny mastering opiera się na wydobywaniu tego, co w pliku już jest. Ze stratnego sygnału AI, wyczyszczonego z wysokich alikwotów przez kompresję, nie odzyskasz cudownie jakości płyty CD. Czego model nie wygenerował, tam korektor nie pomoże.
Często zadawane pytania o błędy i jakość muzyki AI
Dlaczego piosenki AI często psują się na końcu utworu?
Wynika to ze znikającej spójności modeli i ograniczeń okna kontekstowego. Im dalej w utwór, tym model gorzej pamięta swoją początkową strukturę. Dlatego po drugiej minucie często gubi riff lub zmienia tonację.
Czy kolejne wersje AI naprawią metaliczny pogłos?
Tak. Nowe architektury coraz sprawniej operują na surowych, nieskompresowanych próbkach audio, zamiast zgadywać brakujące dane. To powoli zmniejsza zjawisko sztucznego echa.
Czy generowanie tego samego promptu da lepszą jakość?
Dokładnie tak. Generacja probabilistyczna oznacza rzut kostką za każdym razem. Ponowne wygenerowanie (re-render) to często najlepsza, pozbawiona jakiejkolwiek wiedzy technicznej metoda na wylosowanie pliku bez cyfrowych zgrzytów.
Podsumowanie: Perspektywy rozwoju i realne granice technologii
Stoimy w obliczu bariery infrastrukturalnej. Brak otwartych, zdywersyfikowanych danych z pojedynczymi śladami (stems) spowalnia skok jakościowy w generatorach. To fizyka i kompresja dźwięku wyznaczają dziś ostateczny sufit. Zostanie on przebity, to kwestia czasu.
W Refreniku traktujemy błędy generacji z pełną uczciwością. Płacisz 79 zł za gotowy utwór, który ma trafić w punkt. Jeśli sztuczna inteligencja wypluje szumiący błąd i przekręci imię, poprawiasz to i generujesz nową wersję bez dopłat. To część procesu. Jeśli mimo poprawek dalej jest słabo – zgłaszasz się w ciągu 14 dni, a my robimy zwrot na konto bez pytań.
- Modele AI są rewelacyjnymi kompozytorami, ale miernymi inżynierami dźwięku.
- Walka z kompresją wymusza mądre promptowanie, które ukrywa niedoskonałości.
- Jakość studyjna (lossless) z modeli to wciąż melodia przyszłości, więc warto mieć realistyczne oczekiwania wobec technologii w obecnym kształcie.


